Data Curation
Synthesize task instances with rule-based planners that sample an initial configuration, solve it with a valid action sequence, and render the state trajectory into a video.
Overview
Modern video diffusion models can produce convincing motion, yet they still struggle with functional correctness: paths can cross walls, objects can violate temporal logic, and generated videos can look right while failing the underlying task. This suggests an analogy to reasoning-oriented LLMs where pre-training provides broad generative competence, SFT teaches the format of reasoning traces, and RLVR is the essential third stage required to optimize objective correctness.
We build a multi-task video reasoning setting with training pipeline that combines rule-based trajectory generation, SDE-GRPO optimization, and an Early-Step Focus strategy that reduces training time by about 40% while preserving the performance. VideoRLVR improves over sft and competitive proprietary and open-source video generation models on three domains, while also demonstrating impressive generalization in out-of-domain on VBVR.
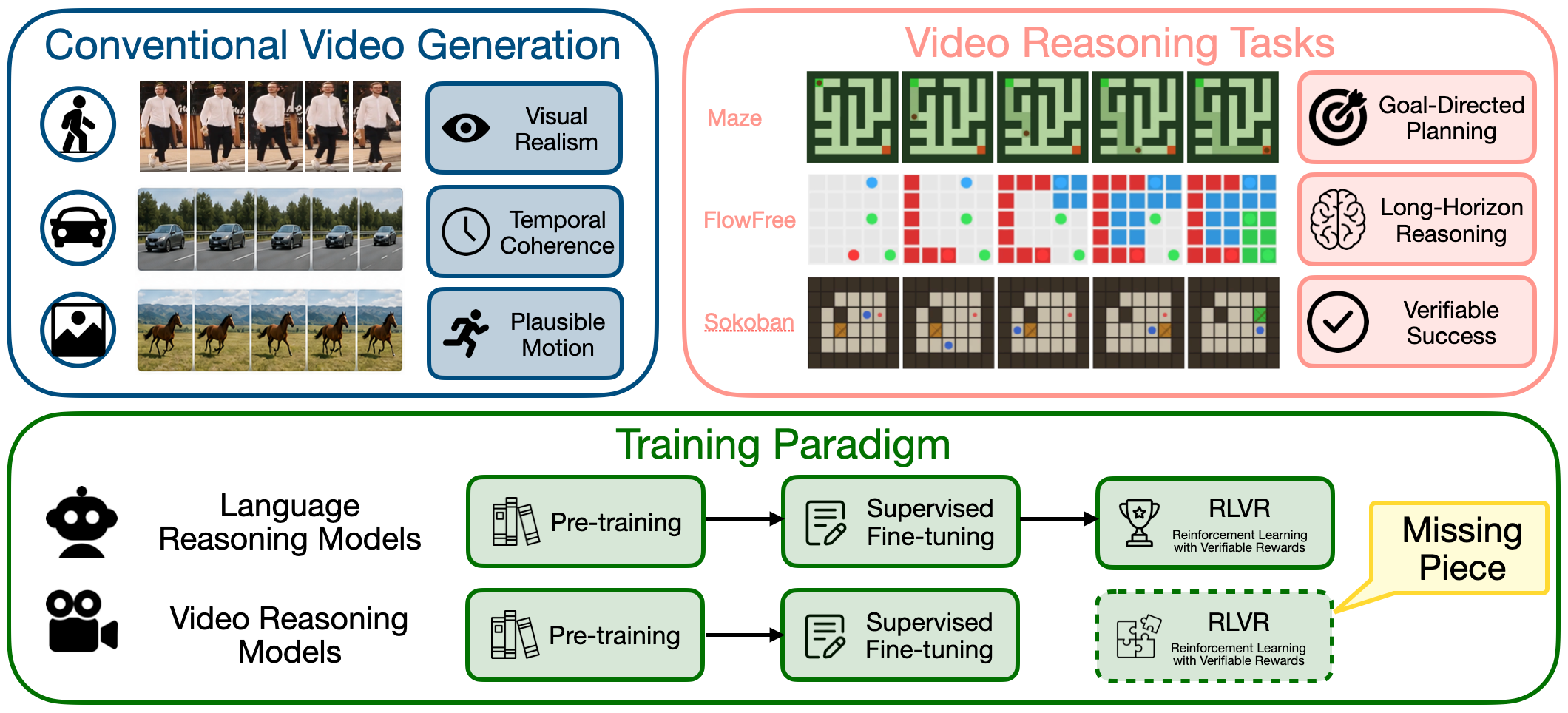
Recipe
Synthesize task instances with rule-based planners that sample an initial configuration, solve it with a valid action sequence, and render the state trajectory into a video.
Use the ground truth trajectories to build a strong visual prior before reward optimization.
Only inject SDE noise and do backpropagation at early steps, where exploration happens, and long-range structure is determined.
Decompose each task into structural components that measure partial progress toward a valid solution.
Results
| Model | Maze | FlowFree | Sokoban | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | SR | Prec | Rec | F1 | SR | Prec | Rec | F1 | SR | |
| Proprietary Models | ||||||||||||
| Sora 2 | 15.8 | 17.2 | 16.5 | 3.1 | 10.8 | 5.1 | 5.8 | 0.0 | 8.5 | 4.8 | 5.4 | 0.0 |
| Kling V3 | 24.8 | 15.7 | 19.2 | 23.5 | 18.8 | 2.7 | 4.7 | 0.0 | 5.7 | 2.7 | 3.7 | 0.0 |
| Veo 3.1 | 22.8 | 18.1 | 20.2 | 26.0 | 23.9 | 4.7 | 7.5 | 4.0 | 22.2 | 6.0 | 9.4 | 0.0 |
| Open-Source Models | ||||||||||||
| CogVideoX1.5 | 13.3 | 10.8 | 11.9 | 0.0 | 18.7 | 2.2 | 3.9 | 0.0 | 3.2 | 0.3 | 0.5 | 0.0 |
| HunyuanVideo | 17.3 | 11.4 | 13.8 | 2.2 | 12.5 | 2.9 | 4.8 | 0.0 | 8.2 | 2.7 | 3.2 | 0.0 |
| Wan2.2-TI2V-5B | 18.3 | 12.2 | 14.6 | 0.0 | 17.4 | 2.0 | 3.4 | 0.0 | 4.1 | 0.7 | 1.0 | 0.0 |
| SFT Models | ||||||||||||
| Wan-R1 | 20.9 | 65.6 | 31.7 | 31.9 | 20.9 | 3.6 | 6.1 | 0.0 | 7.7 | 2.1 | 3.3 | 0.0 |
| VBVR-Wan2.2 | 62.7 | 77.8 | 69.4 | 60.8 | 17.9 | 5.6 | 8.5 | 1.7 | 16.2 | 1.7 | 3.1 | 0.0 |
| SFT Epoch 5 | 80.2 | 83.0 | 81.6 | 66.1 | 42.8 | 42.2 | 42.4 | 2.4 | 33.6 | 11.9 | 17.6 | 2.9 |
| SFT Epoch 10 | 80.4 | 85.1 | 82.7 | 69.0 | 43.1 | 42.5 | 42.8 | 2.5 | 32.8 | 11.6 | 17.1 | 2.7 |
| RL Model | ||||||||||||
| VideoRLVR | 82.1 | 86.9 | 84.4 | 72.2 | 44.3 | 43.8 | 44.0 | 7.9 | 34.0 | 12.5 | 29.4 | 6.1 |
OOD Evaluation
| Model | Avg. | Abst. | Know. | Perc. | Spat. | Trans. |
|---|---|---|---|---|---|---|
| 5B Models | ||||||
| CogVideoX1.5 | 26.2 | 28.1 | 23.5 | 25.0 | 25.4 | 28.2 |
| VideoRLVR | 60.2 | 65.5 | 62.0 | 59.7 | 58.8 | 58.2 |
| 14B Models | ||||||
| Wan2.2-I2V-A14B | 32.9 | 40.5 | 30.8 | 34.3 | 23.6 | 30.7 |
| VBVR-Wan2.2 | 61.0 | 76.8 | 57.2 | 54.7 | 61.8 | 61.5 |
LLM Comparison
| Model | Maze | |||
|---|---|---|---|---|
| Prec | Rec | F1 | SR | |
| GPT 4o | 11.7 | 13.0 | 12.3 | 0.0 |
| GPT 5.5 Pro | 76.0 | 70.1 | 72.9 | 66.0 |
| Gemini 2.5 Flash | 11.2 | 10.5 | 10.9 | 0.0 |
| Gemini 3.1 Pro | 26.8 | 27.0 | 26.9 | 23.0 |
| VideoRLVR | 82.1 | 86.9 | 84.4 | 72.2 |
Resources
@article{zhu2026video,
title={Video Models Can Reason with Verifiable Rewards},
author={Tinghui Zhu and Sheng Zhang and James Y. Huang and Selena Song and Xiaofei Wen and Yuankai Li and Hoifung Poon and Muhao Chen},
journal={arXiv preprint arXiv:2605.15458},
year={2026}
}